Основы работы с Linux. / BASH. Регулярные выражения. / BASH. Регулярные выражения.
BASH. Регулярные выражения. Команда grep.
Позволяют формировать условия для следующих операций:
-
проводить текстовый поиск;
-
проверять вводимые пользователем данные;
-
заменять или извлекать участки текста;
-
разделять текст на блоки.
"Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems." -Jamie Zawinski, 1997
В bash регулярные выражения допустимы в составной команде [[ при использовании сравнения =~ , например, в операторе if .
Однако регулярные выражения являются важной частью более широкого инструментария для таких команд, как grep , awk и особенно sed .
Это очень мощные команды, поэтому их необходимо знать.
Возмем такой пример текста.
Пример 3.1. Файл frost.txt
1 Two roads diverged in a yellow wood,
2 And sorry I could not travel both
3 And be one traveler, long I stood
4 And looked down one as far as I could
5 To where it bent in the undergrowth;
7
6 Excerpt from The Road Not Taken by Robert Frost
Используемые команды.
Команда grep.
Команда grep выполняет поиск по содержимому файлов с помощью заданного шаблона и выводит любую строку, которая ему соответствует. Чтобы использовать команду grep , вам нужно указать шаблон и одно или несколько имен файлов (имена файлов могут быть переданы через канал передачи данных).
Параметры команды
-c — вывести количество строк, соответствующих шаблону;
-E — включить расширенное регулярное выражение (без необходимости экранирования специальных символов);
-f — читать шаблон поиска, находящийся в предоставленном файле. Файл может содержать несколько шаблонов, причем каждая строка включает в себя один шаблон;
-i — игнорировать регистр символов;
-l — вывести только имя файла и путь, по которому был найден шаблон;
-n — вывести номер строки файла, в которой был найден шаблон;
-P — включить механизм регулярных выражений Perl;
-R , -r — выполнить рекурсивный поиск подкаталогов.
Сигнатура вызова.
grep параметры шаблон имена_файлов
Для поиска в каталоге /home и во всех его подкаталогах файлов, содержащих слово password независимо от регистра, выполните команду:
grep -R -i 'password' /home
password - это литерал
Литерал это самый простой шаблон поиска при котором ищем слово.
Регулярные выражения в языках отличных от BASH принято обрамлять прямыми слешами.
Типа такого:
/password/
Метасимволы регулярных выражений.
Если простой символ - это просто символ который вы ищете, то метасимвол значит нечто большее, а именно определенное правило.
Метасимвол точка.
Cоответствует любому символу, кроме символа новой строки.
$ grep 'T.o' frost.txt
1 Two roads diverged in a yellow wood,
Шаблоны регулярных выражений также чувствительны к регистру, поэтому строка 3 файла не возвращается, хотя она содержит слово too.
Если вы хотите трактовать этот метасимвол как символ точки, а не как символ подстановки, то добавьте перед ним обратный слеш ( . ).
Метасимвол знак вопроса.
В регулярном выражении знак вопроса ( ? ) делает любой предшествующий ему символ необязательным.
$ egrep 'T.?o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
egrep - без учера регистра (аналогично grep -E)
Метасимвол звездочки.
В регулярных выражениях звездочка ( * ) — это специальный символ, (похож на ?) который соответствует предыдущему элементу неограниченное количество раз.
$ grep 'T.*o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
7 Excerpt from The Road Not Taken by Robert Frost
Метасимвол плюс «+».
Метасимвол плюс ( + ) работает так же, как и * , за исключением того, что предыдущий ему элемент должен встретиться хотя бы однажды.
Другими словами, он соответствует предыдущему элементу, который появляется один раз или более:
$ egrep 'T.+o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
7 Excerpt from The Road Not Taken by Robert Frost
Группирование (круглые скобки)
Для группирования символов можно использовать скобки. Помимо прочего, это позволит нам рассматривать символы, расположенные внутри скобок, как один элемент, на который далее можно ссылаться.
Вот пример группировки:
$ egrep 'And be one (stranger|traveler), long I stood' frost.txt
3 And be one traveler, long I stood
| - логическое ИЛИ
Классы символов (квадратные скобки).
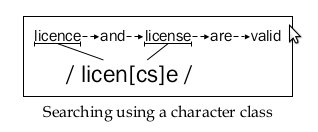
Квадратные скобки [ ] предназначены для определения классов и списков допустимых символов.
Ими можно указать, какие символы в данной позиции в шаблоне совпадают.
Это особенно полезно при попытке проверить пользовательский ввод. Для краткости при указании диапазона можно добавить тире, например [a–j] .
список распространенных примеров использования классов символов и диапазонов.
[abc] - Соответствует только символу a, или b, или c
[1–5] - Соответствует цифрам в диапазоне от 1 до 5
[a–zA–Z] - Соответствует любой строчной или прописной букве от a до z
[0–9 +–*/] - Соответствует числам или указанным четырем математическим символам
[0–9a–fA–F] - Соответствует шестнадцатеричному символу
Кроме того, есть предопределенные символьные классы, известные как сокращения для наборов символов.
Сокращения регулярных выражений
\s - Пробельный символ
\S - Непробельный символ
\d - Цифровой символ
\D - Нецифровой символ
\w - Слово
\W - Не слово
\x - Шестнадцатеричное число (например, 0x5F)
Например найти любые числа в файле frost.txt
$ grep -P '\d' frost.txt
Другие символьные классы (с более подробным синтаксисом) действительны только внутри скобок
[:alnum:] - Любой буквенно-цифровой символ
[:alpha:] - Любой алфавитный символ
[:cntrl:] - Любой управляющий символ
[:digit:] - Любая цифра
[:graph:] - Любой графический символ
[:lower:] - Любой символ нижнего регистра
[:print:] - Любой печатаемый символ
[:punct:] - Любой знак препинания
[:space:] - Любой пробельный символ
[:upper:] - Любой символ верхнего регистра
[:xdigit:] - Любая шестнадцатеричная цифра
Пример:
grep 'X[[:upper:][:digit:]]' idlist.txt
Согласно этой команде будет выполнен поиск содержимого в файле idlist.txt и в результате будет выведена любая строка, содержащая символ X, за которым следует любая прописная буква или цифра.
Обратные ссылки
Обратные ссылки на регулярные выражения являются одной из самых мощных и часто сбивающей с толку операцией регулярных выражений. Рассмотрим 1 следующий файл tags.txt :
<i>line</i>
is
<div>great</div>
<u>!</u>
Предположим, вы хотите написать регулярное выражение, которое будет извлекать любую строку, содержащую соответствующую пару полных тегов HTML. Вы можете сосредоточиться на формате тега HTML и использовать обратную ссылку на регулярное выражение, как показано ниже:
$ egrep '<([A-Za-z]*)>.*<!--\1-->' tags.txt
<i>line</i>
<div>great</div>
<u>!</u>
В этом примере обратная ссылка \1 расположена в последней части регулярного выражения. Эта ссылка направляет нас к выражению, заключенному в первый набор скобок, [A-Za-z]* .
Квантификаторы
Квантификаторы указывают, сколько раз элемент должен появиться в строке, и определяются фигурными скобками {} .
Например, шаблон T{5} означает, что буква T должна последовательно появляться ровно пять раз.
T{3,6} - от трех до шести раз
T{5,} - пять раз или более.
Якоря и границы слов
Если нужно указать, что шаблон должен находиться в начале или в конце строки, используют якоря.
Символ каретки ( ^ ) предназначен для привязки шаблона к началу строки. Например, ^[1-5] означает, что соответствующая строка должна начинаться с одной из цифр от 1 до 5. Символ $ используется для привязки шаблона к концу последовательности или строки.
Например, [1-5]$ означает, что строка должна заканчиваться одной из цифр от 1 до 5.
Шляпка (^) может еще обозначать логическое отрицание!!!
$ - конец строки
Пример.
^Name:[\sa-zA-Z]+$
Примеры регулярных выражений.
Проверка телефона.
/\d+[-\s]?\d+[-\s]?\d+/
[-\s] - дефис или пробел
Варианты проверки email
/^[\w-\.]+@([\w-]+\.)+[\w-]{2,4}$/
ˆ[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)* @ [a-zA-Z0-9-]+\.([azA-Z]{2,3})$
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Вот такая “жесть” для понимания этой регулярки!
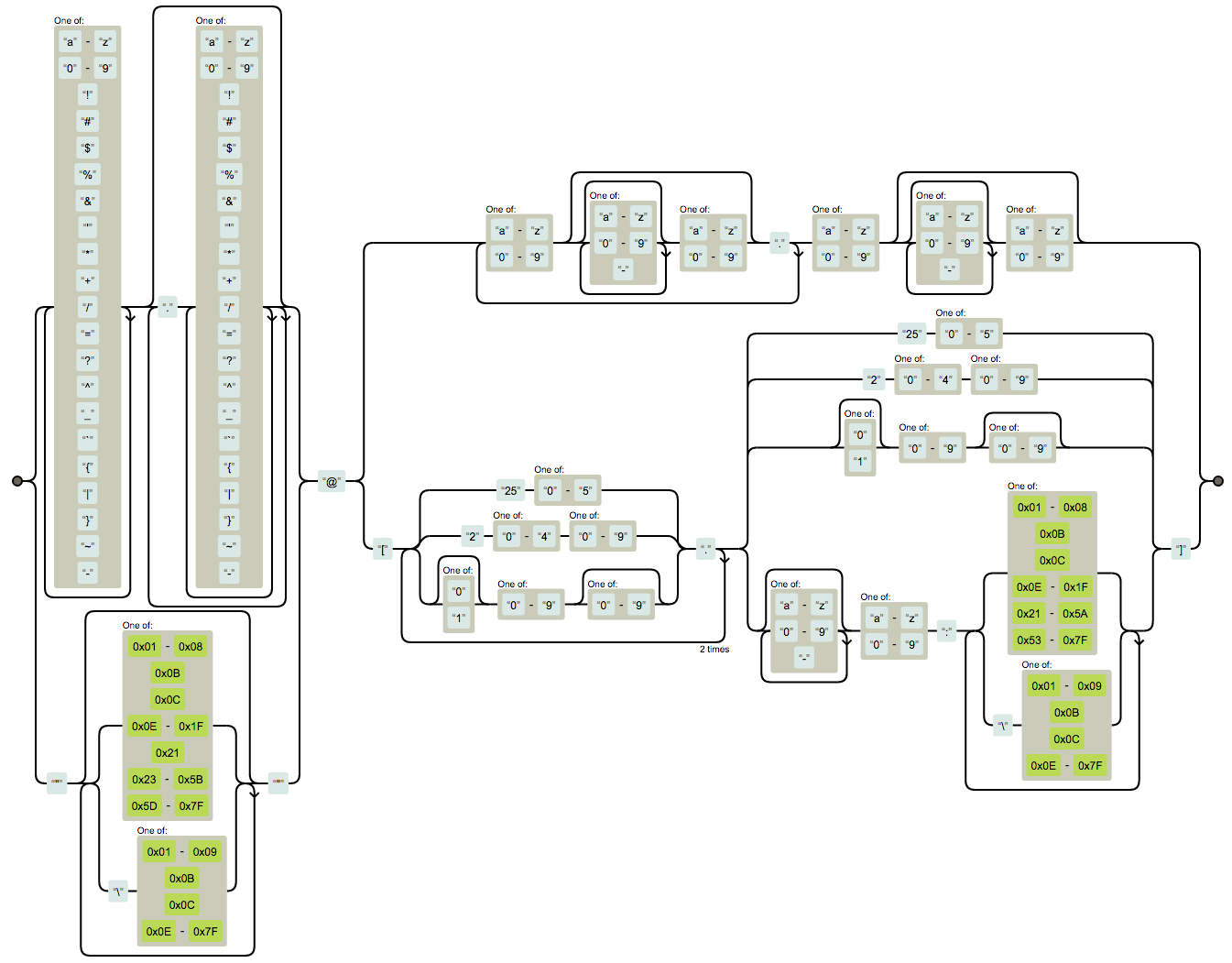
Проверка ip адреса
((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(\.|$)){4}
Регулярные выражение в Python.
Импорт пакета.
import re
Далее мы должны откомпилировать регулярку в байт-код, способный к выполнению в C.
pattern = re.compile('foo')
При компиляции можно указывать флаги.
pattern = re.compile("^\w+\: (\w+/\w+/\w+)", re.MULTILINE)
re.MULTILINE - будет компилировать для поиска во всех строках, если его не указать, то искать будет только в первой.
После компиляции нам возвращается объект, который поддерживает поиск и прочие операции.
Поиск совпадений.
pattern.match("foo bar")
pattern.search("Hello world")
Эта конструкция возвратит объект MatchObject совпадения либо None.
Достаем совпадения из MatchObject группами.
match.group()
match.group(0)
match.group(1)
Возвращаем список совпадений.
list = pattern.findall("hello world")
Регулярные выражение в javascript.
Тут все намного проще.
var email = "joerg@krause.net";
console.log(check(email));
function check(email) {
if (email.match(/^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*@[a-zA-Z0-9-]+\\
.([a-zA-Z]{2,3})$/)) {
return true;
} else {
return false;
}
}
Как видно строки в js-ке умеют принимать регулярку в методе match
Для любопытствующих, приведу подробное изложение последовательности этой проверки.

Ручное создание шаблона и тестирование.
var patt = /^auto$/;
console.log(patt.test("auto"));
Второй вариант с exec().
<script>
var re = /^[0-9]{5}$/;
var field = "12683";
var checkzip = re.exec(feld);
if(!checkzip) {
alert("The zip code " + checkplz + " is not correct.");
} else {
console.log(checkplz)
}
</script>
Объект для работы с регулярками RegExp
Методы обьекта
exec() - тестирует и возвращает первое попадание
test() - тестирует и возвращает true или false
toString() - возвращяет выражение как строку
Пример.
var text = "Than Ann answers all questions again.";
var patt = /a/g;
var match = patt.exec(text);
console.log(match[0] + " found at " + match.index);
match = patt.exec(text);
do {
match = patt.exec(text);
if (!match) break;
console.log(match[0] +" found at " + match.index);
} while(true);
Вывод.
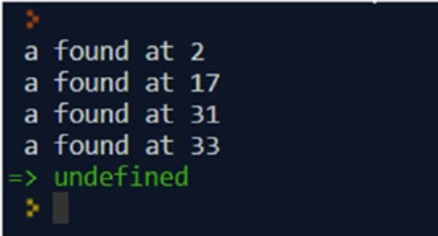
Как видим, для того, чтобы пробегаться по всем совпадениям, необходимо “крутить” цикл, где вызывать exec() и прерывать его когда совпадения закончатся.
if (!match) break;