Basics of Python and Django. / Практикум. Создаем телеграм бота. / Проверяем домены с истекающим сроком.
Проверяем домены с истекающим сроком.
Недавно от “насяльника” мне поступила такая задача:
“Димыч скажи пож вот отсюда - https://www.reg.ru/domain/deleted/?&free_from=07.06.2019&free_to=07.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page=5 можно сграбить названия доменов?”
Я зашел по ссылке, увидел список доменов у которых истекает срок, постраничную навигацию и все дела.
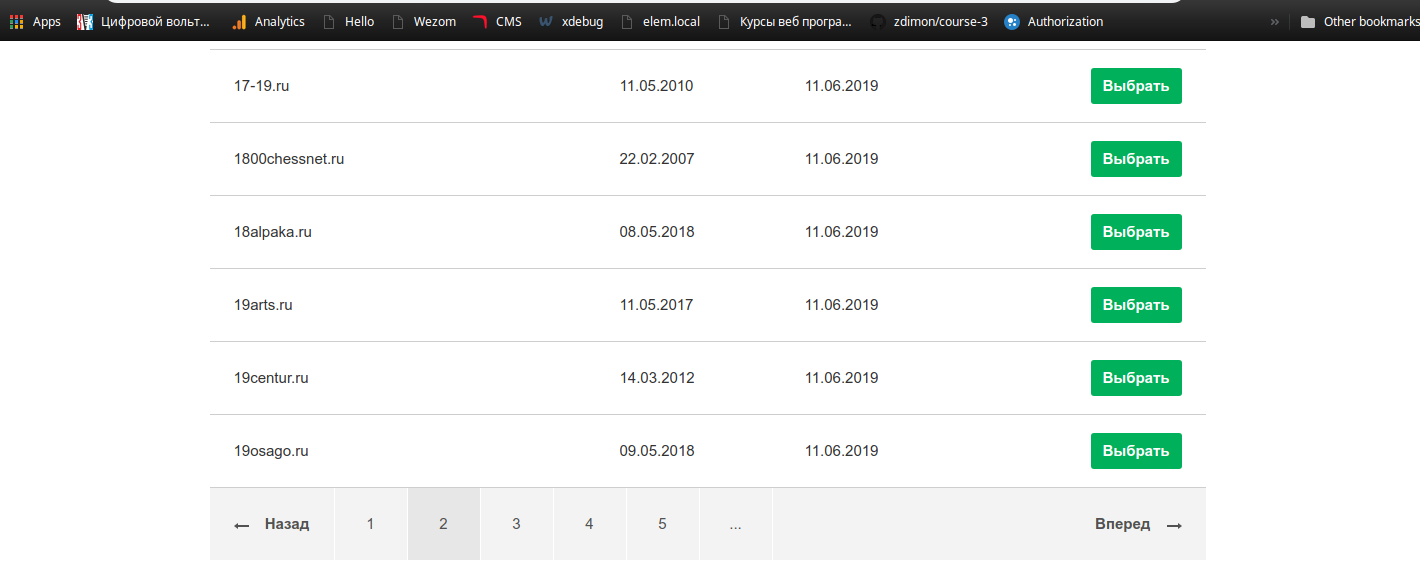
Я подумал “Почему бы и нет?” буду пробегать по постраничке, меняя параметр page=1,2,3 в урле, парсить страницы и сохранять домены.
Что может быть проще?
Затем поступило дополнение к задаче. Как оказалось, эти домены нужно проверять на присутствие вот на одном сайте, скажем yandex.ru:
Например вот так:
https://yandex.ru/sabai.tv
Куда вместо sabai.tv подставлять мои сграбленные доменчики.
С этим вроде тоже проблем быть не должно. Тем более, что при отсутствии домена в этом интернет-каталоге, он возвращает 404 ошибку.
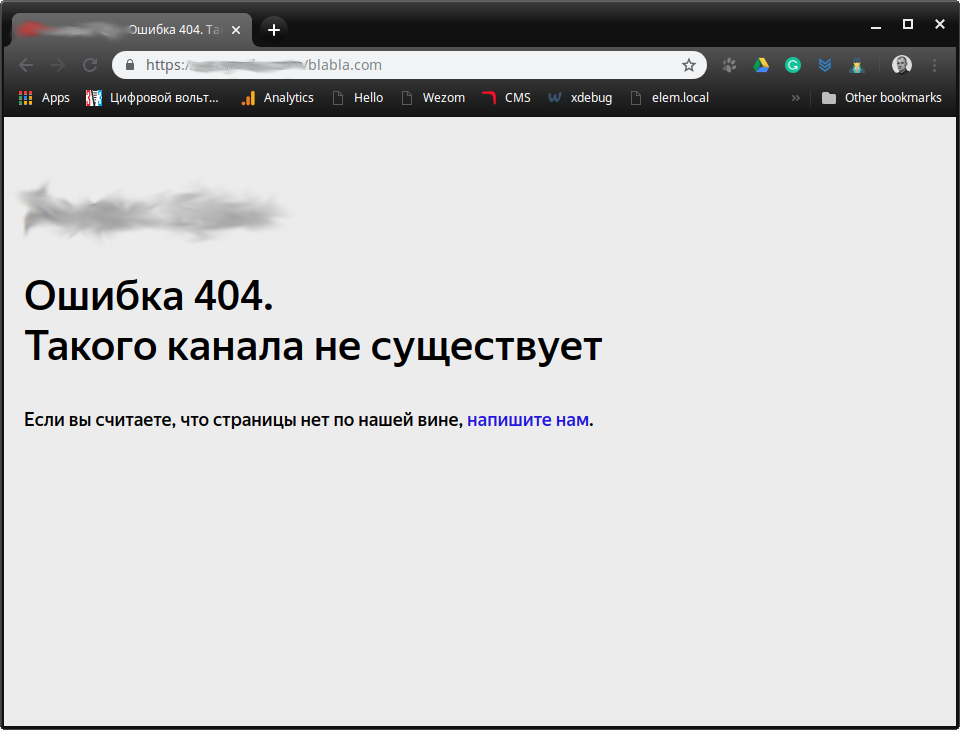
Прийдется немного заддосить напрячь этот сайтик.
Итак, поехали.
Мне понадобятся две питоновские библиотеки:
requests - для создания HTTP GET запросов
beautifulsoup4 - для парсинга HTML и поиска полезной информации на странице.
Все это добро сложим в виртуальное окружение.
Создаю и активирую его.
mkdir finedomain
cd finedomain
virtualenv venv
source ./venv/bin/activate
Ставлю пакеты.
pip install requests beautifulsoup4
Пишу код с запросом в файле grabing.py.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# импортируем все что надо для работы
import requests
from bs4 import BeautifulSoup
import json
import time
import sys
# начало программы
print('Start')
# определяю строку с урлом
# к ней с конца буду прилеплять страницы
url = 'https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page='
# запрос первой страницы
r = requests.get(url+'0')
print(r.text)
Результат.
Неплохо, HTML получили, далее нужно распарсить это все добро beautifulsoup-ом.
soup = BeautifulSoup(r.text, 'html.parser')
Теперь, в переменной soup у нас не только весь код страницы, но и инструменты для поиска ее элементов.
Откываем инспектор браузера и смотрим где у нас список.
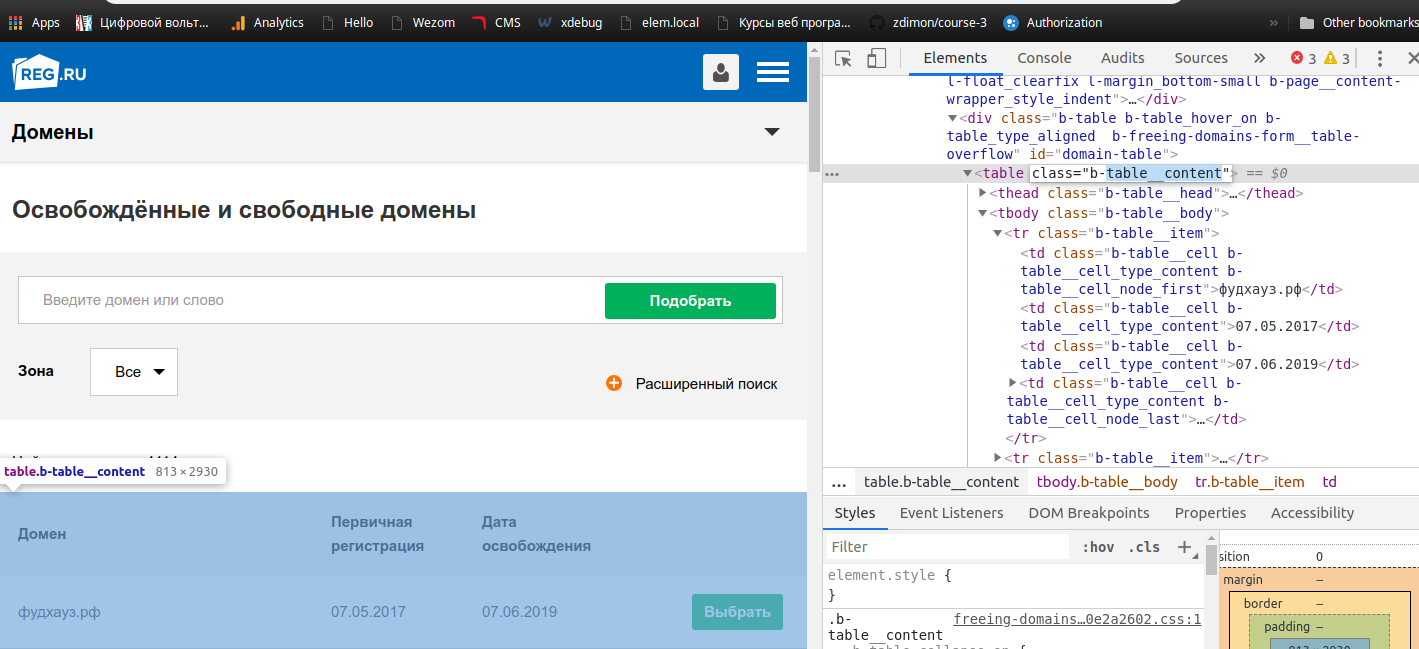
Ага, таблица с классом b-table__content. Нет ничего проще ее вытянуть так.
table = soup.find("table",{"class": "b-table__content"})
find() - ищет один элемент findAll() - найдет список
Далее получу tr-ки (строки) из тега tbody.
tbody = table.find("tbody")
trs = tbody.findAll("tr")
Побегу по ним циклом, найду td-шки (ячейки таблицы) и выведу из первой по счету доменное имя.
soup = BeautifulSoup(r.text, 'html.parser')
table = soup.find("table",{"class": "b-table__content"})
tbody = table.find("tbody")
trs = tbody.findAll("tr")
for tr in trs:
tds = tr.findAll("td")
print(tds[0].text)
Сработало!
Теперь создам список для хранения доменов и даты истечения, и в цикле заполню его.
Полный код получился таким.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# импортируем все что надо для работы
import requests
from bs4 import BeautifulSoup
import json
import time
# начало программы
print('Start')
# определяю строку с урлом
# к ней с конца буду прилеплять страницы
url = 'https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page='
# запрос первой страницы
r = requests.get(url+'0')
# тут буду хранить домены
data = []
# парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# находим первую таблицу по тегу и css классу
table = soup.find("table",{"class": "b-table__content"})
# в ней блок tbody по имени тега
tbody = table.find("tbody")
# строки
trs = tbody.findAll("tr")
for tr in trs:
# ячейки
tds = tr.findAll("td")
# добавляем домен и срок истечения в список
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
print(data)
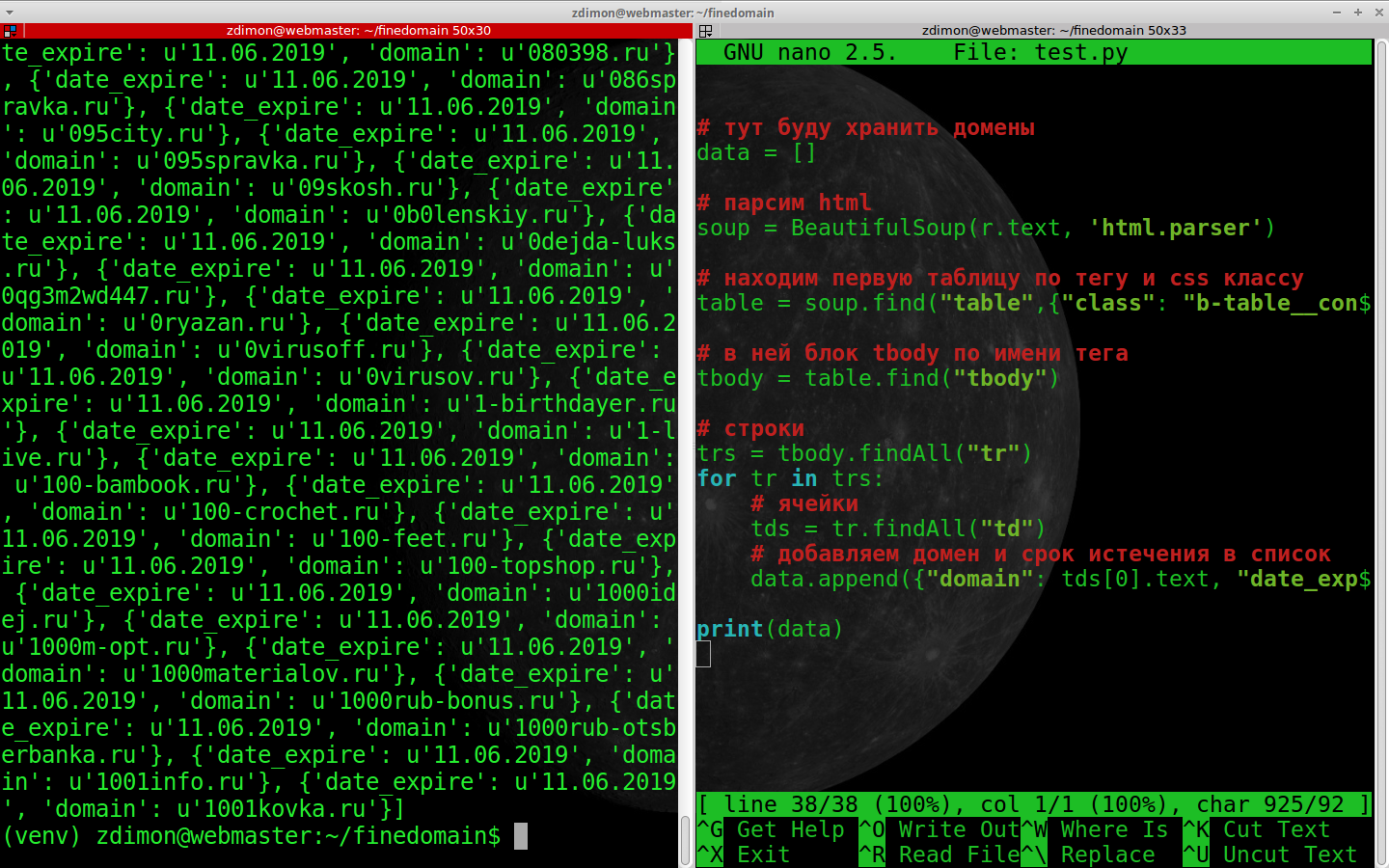
Время проверить эти домены на сайте.
Сделаю для этого функцию, принимающую доменное имя параметром.
def check_domain(domain):
# формирую url, адрес подставляя домен в строку
url = 'https://yandex.ru/%s' % domain
# пробую сделать запрос
try:
# получаю страницу
r = requests.get(url)
if r.status_code == 404: # проверяю статус
print('Domain %s result %s' % (domain, 'FAIL!'))
return False
else:
print('Domain %s result %s' % (domain, 'SUCCESS'))
# если повезло и домен нашли
return True
# это если запрос обрушился по какой то причине
except:
print('Request error %s' % url)
return False
Осталось вызвать эту функцию в цикле.
for tr in trs:
# ячейки
tds = tr.findAll("td")
# добавляем домен и срок истечения в список
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# проверяю домен
check_domain(tds[0].text)
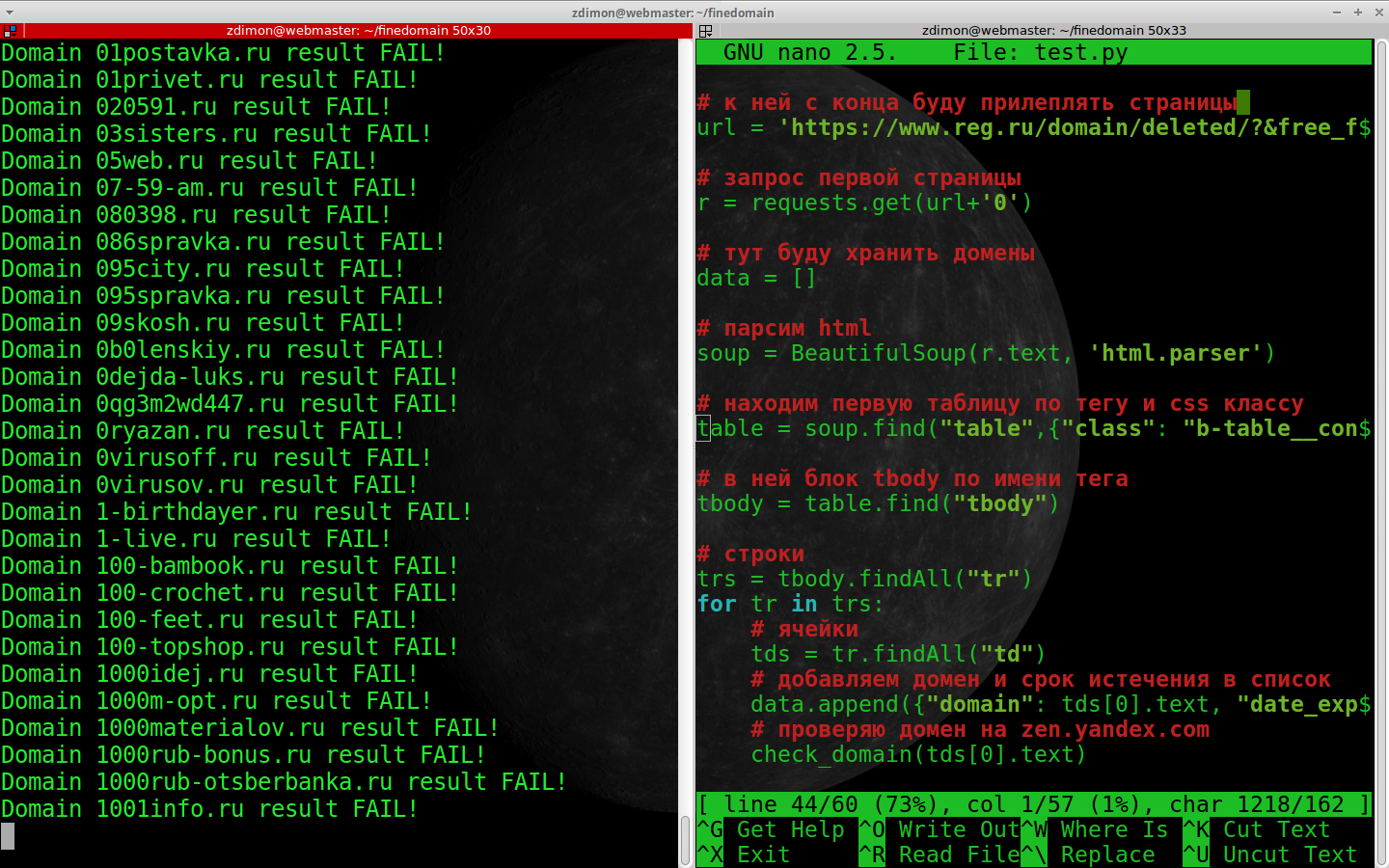
Результат не утешает и попаданий на первой странице нет, зато работает!
Теперь мне нужно определить конец постраничной “нафигации” и прогнать процесс по всем доменам на указанную дату.
В лучших традициях функционального программирования делаю функцию.
def check_end(soup):
''' Определяю конец постранички '''
try:
# на конечной странице был замечен заголовок h1 с текстом
'''
Доменов, отвечающих заданным критериям фильтрации, не найдено.
'''
h2 = soup.find("h2")
# тут для поиска сказало что нужно вначале кодировать в UTF-8
if h2.text.encode('utf-8').find('отвечающих заданным критериям')>0:
return True
else:
return False
except:
return False
Мучу цикл while пока не дошло до конца со счетчиком страниц.
is_end = False
page = 0
while not is_end:
# определяю строку с урлом
# к ней с конца буду прилеплять страницы
url = 'https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page=%s' % page
print("Делаю страницу %s" % page)
# добавляем счетчик страниц
page = page + 1
# запрос первой страницы
r = requests.get(url)
# тут буду хранить домены
data = []
# парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# проверим конец постранички
if check_end(soup):
is_end = True
break # ломаем цикл
# находим первую таблицу по тегу и css классу
table = soup.find("table",{"class": "b-table__content"})
# в ней блок tbody по имени тега
tbody = table.find("tbody")
# строки
trs = tbody.findAll("tr")
for tr in trs:
# ячейки
tds = tr.findAll("td")
# добавляем домен и срок истечения в список
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# проверяю домен
check_domain(tds[0].text)
Решил прервать процесс по ctrl+c, получил такой облом.
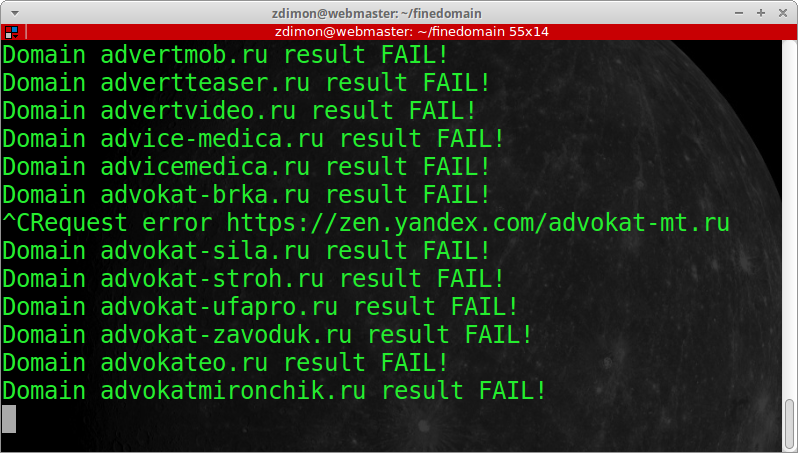
Пришлось тушить терминал, обидное недоразумение.
Случилось оно в этом блоке при проверке домена:
except:
print('Request error %s' % url)
return False
А если я отработаю исключение KeyboardInterrupt?
try:
# получаю страницу
...
except KeyboardInterrupt: # выход по ctrl+c
print("Ну пока!")
sys.exit() # нагло вываливаемся из проги
# это если запрос обрушился по какой то другой причине
except:
print('Request error %s' % url)
return False
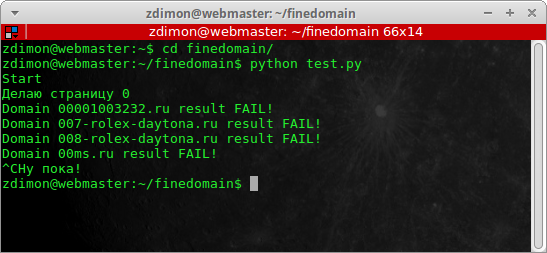
Намного лучше!
Осталось забрать дату у пользователя где то в начале скрипта.
print("Вводи дату типа 12.06.2019: ")
user_date = raw_input() #
print("Работаем по {}".format(user_date))
Просто input() не канает! Пользуйтесь только raw_input.
И вставить ее в урл запроса.
В конце я выгружу успешные домены в файлик.
def save_success(domain):
with open('success.txt', 'a+') as of: # открываем для добавления и создаем если нет
of.write(domain+';')
print('Domain %s result %s' % (domain, 'SUCCESS'))
Полный код программы.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# импортируем все что надо для работы
import requests
from bs4 import BeautifulSoup
import json
import time
import sys
# начало программы
print('Начинаем грабить домены.')
print("Вводи за какую дату? (типа 12.06.2019): ")
user_date = raw_input()
print("Работаем по {}".format(user_date))
def save_success(domain):
with open('success.txt', 'a+') as of: # открываем для добавления и создаем если нет
of.write(domain+';')
print('Domain %s result %s' % (domain, 'SUCCESS'))
def check_domain(domain):
# формирую url, адрес подставляя домен в строку
url = 'https://yandex.ru/%s' % domain
# пробую сделать запрос
try:
# получаю страницу
r = requests.get(url)
if r.status_code == 404: # проверяю статус
print('Domain %s result %s' % (domain, 'FAIL!'))
return False
else:
print('Domain %s result %s' % (domain, 'SUCCESS'))
# если повезло и домен нашли
return True
except KeyboardInterrupt: # выход по ctrl+c
print("Ну пока!")
sys.exit() # нагло вываливаемся из проги
# это если запрос обрушился по какой то причине
except:
print('Request error %s' % url)
return False
def check_end(soup):
''' Определяю конец постранички '''
try:
# на конечной странице был замечен заголовок h1 с текстом
'''
Доменов, отвечающих заданным критериям фильтрации, не найдено.
'''
h2 = soup.find("h2")
# тут для поиска сказало что нужно вначале кодировать в UTF-8
if h2.text.encode('utf-8').find('отвечающих заданным критериям')>0:
return True
else:
return False
except:
return False
is_end = False
page = 0
while not is_end:
# определяю строку с урлом
# к ней с конца буду прилеплять страницы
url = 'https://www.reg.ru/domain/deleted/?&free_from=%s&free_to=%s&order=ASC&sort_field=dname_idn%20%20%20%20&page=%s' % (user_date,user_date,page)
print("Делаю страницу %s" % page)
# добавляем счетчик страниц
page = page + 1
# запрос первой страницы
r = requests.get(url)
# тут буду хранить домены
data = []
# парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# проверим конец постранички
if check_end(soup):
is_end = True
break # ломаем цикл
# находим первую таблицу по тегу и css классу
table = soup.find("table",{"class": "b-table__content"})
# в ней блок tbody по имени тега
tbody = table.find("tbody")
# строки
trs = tbody.findAll("tr")
for tr in trs:
# ячейки
tds = tr.findAll("td")
# добавляем домен и срок истечения в список
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# проверяю домен
if check_domain(tds[0].text):
save_success(tds[0].text)
print('The end')
Выводы.
В статье освещены приемы программирования на языке Python на примере реальной, практической задачи.
Изложены основные функции Python библиотек requests и BeautifulSoup для получения содержимого страницы , поиска и извлечения из нее полезной информации с сохранением в текстовый файл.