Основи роботи з Linux. / BASH. Регулярні вирази. / BASH. Регулярні вирази.
BASH. Регулярні вирази. Команда grep.
Дозволяють формувати умови для наступних операцій:
-
проводити текстовий пошук;
-
перевіряти дані, що вводяться користувачем;
-
замінювати чи витягувати ділянки тексту;
-
Розділяти текст на блоки.
"Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems." -Jamie Zawinski, 1997
В bash регулярні вирази допустимі у складовій команді [[ при використанні порівняння =~, наприклад, в операторі if.
Однак регулярні вирази є важливою частиною ширшого інструментарію для таких команд, як grep, awk і особливо sed.
Це дуже потужні команди, тому їх потрібно знати.
Візьмемо такий приклад тексту.
Пример 3.1. Файл frost.txt
1 Two roads diverged in a yellow wood,
2 And sorry I could not travel both
3 And be one traveler, long I stood
4 And looked down one as far as I could
5 To where it bent in the undergrowth;
7
6 Excerpt from The Road Not Taken by Robert Frost
Використовувані команди.
Команда grep.
Команда grep виконує пошук за вмістом файлів за допомогою заданого шаблону та виводить будь-який рядок, який йому відповідає. Щоб використати команду grep, вам потрібно вказати шаблон і одне або кілька імен файлів (Імена файлів можуть бути передані через канал передачі даних).
Параметри команди
-c — вивести кількість рядків, які відповідають шаблону;
-E — увімкнути розширений регулярний вираз (без необхідності екранування спеціальних символів);
-f — читати шаблон пошуку, який знаходиться у наданому файлі. Файл може містити кілька шаблонів, причому кожен рядок включає в себе один шаблон;
-i — ігнорувати регістр символів;
-l — вивести лише ім’я файлу та шлях, яким було знайдено шаблон;
-n — вивести номер рядка файлу, в якому було знайдено шаблон;
-P - включити механізм регулярних виразів Perl;
-R , -r - виконати рекурсивний пошук підкаталогів.
Сигнатура дзвінка.
grep параметри шаблон імена_файлів
Для пошуку в каталозі /home та у всіх його підкаталогах файлів, що містять слово password незалежно від регістру, виконайте команду:
grep -R -i 'password' /home
password - це літерал
Літерал це найпростіший шаблон пошуку, при якому шукаємо слово.
Регулярні вирази в мовах, відмінних від BASH, прийнято обрамляти прямими слішами.
Типу такого:
/password/
Метасимволи регулярних виразів.
Якщо простий символ - це просто символ, який ви шукаєте, то метасимвол означає щось більше, а саме певне правило.
Метасимвол крапка.
Відповідає будь-якому символу, окрім нового рядка.
$ grep 'T.o' frost.txt
1 Two roads diverged in a yellow wood,
Шаблони регулярних виразів також чутливі до регістру, тому рядок 3 файлу не повертається, хоча містить слово too.
Якщо ви хочете трактувати цей метасимвол як символ точки, а не як символ підстановки, додайте перед ним зворотний сліш (.).
Метасимвол питання питання.
У регулярному вираженні знак питання (?) робить будь-який попередній йому символ необов’язковий.
$ egrep 'T.?o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
egrep - без учора регістру (аналогічно grep-E)
Метасимвол зірочки.
У регулярних виразах зірочка ( * ) - це спеціальний символ, (схожий на ?) який відповідає попередньому елементу необмежену кількість разів.
$ grep 'T.*o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
7 Excerpt from The Road Not Taken by Robert Frost
Метасимвол плюс “+”.
Метасимвол плюс ( + ) працює так само, як і * , за винятком того, що попередній елемент повинен зустрітися хоча б одного разу.
Іншими словами, він відповідає попередньому елементу, який з’являється один раз або більше:
$ egrep 'T.+o' frost.txt
1 Two roads diverged in a yellow wood,
5 To where it bent in the undergrowth;
7 Excerpt from The Road Not Taken by Robert Frost
Групування (круглі дужки)
Для групування символів можна використовувати дужки. Крім іншого, це дозволить нам розглядати символи, розташовані всередині дужок, як один елемент, який далі можна посилатися.
Ось приклад угруповання:
$ egrep 'And be one (stranger|traveler), long I stood' frost.txt
3 And be one traveler, long I stood
| - логічне АБО
Класи символів (квадратні дужки).
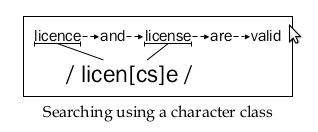
Квадратні дужки [ ] призначені для визначення класів та списків допустимих символів.
Ними можна вказати, які символи у цій позиції у шаблоні збігаються.
Це особливо корисно при спробі перевірити введення користувача. Для короткості при вказівці діапазону можна додати тире, наприклад [a-j] .
список поширених прикладів використання класів символів та діапазонів.
[abc] - Відповідає лише символу a, або b, або c
[1–5] - Відповідає цифрам в діапазоні від 1 до 5
[a–zA–Z] - Відповідає будь-якій малі або великій літері від a до z
[0–9 +–*/] - Відповідає числам або вказаним чотирма математичними символами
[0–9a–fA–F] - Відповідає шістнадцятковому символу
Крім того, є зумовлені символьні класи, відомі як скорочення для набору символів.
Скорочення регулярних виразів
\s - Пробельний символ
\S - Непробільний символ
\d - Цифровий символ
\D - Нецифровий символ
\w - Слово
\W - Не слово
\x - Шістнадцяткове число (наприклад, 0x5F)
Наприклад, знайти будь-які числа у файлі frost.txt
$ grep -P '\d' frost.txt
Інші символьні класи (з більш докладним синтаксисом) дійсні тільки всередині дужок
[:alnum:] - Будь-який буквено-цифровий символ
[:alpha:] - Будь-який алфавітний символ
[:cntrl:] - Будь-який керуючий символ
[:digit:] - Будь-яка цифра
[:graph:] - Будь-який графічний символ
[:lower:] - Будь-який символ нижнього регістру
[:print:] - Будь-який друкований символ
[:punct:] - Будь-який розділовий знак
[:space:] - Будь-який символ пробілу
[:upper:] - Будь-який символ верхнього регістру
[:xdigit:] - Будь-яка шістнадцяткова цифра
Приклад:
grep 'X[[:upper:][:digit:]]' idlist.txt
Відповідно до цієї команди буде виконано пошук вмісту у файлі idlist.txt і в результаті буде виведено будь-який рядок, що містить символ X, за яким слід будь-яка велика літера або цифра.
Зворотні посилання
Зворотні посилання на регулярні вирази є одним із найпотужніших і часто збиває з пантелику операцією регулярних виразів. Розглянемо 1 наступний файл tags.txt:
<i>line</i>
is
<div>great</div>
<u>!</u>
Припустимо, ви хочете написати регулярний вираз, який витягуватиме будь-який рядок, що містить пару повних тегів HTML. Ви можете зосередитись на форматі тега HTML та використовувати зворотне посилання на регулярне вираз, як показано нижче:
$ egrep '<([A-Za-z]*)>.*<!--\1-->' tags.txt
<i>line</i>
<div>great</div>
<u>!</u>
У цьому прикладі зворотне посилання \1 розташоване в останній частині регулярного посилання вирази. Це посилання направляє нас до виразу, укладеного в перший набір дужок [A-Za-z]* .
Квантифікатори
Квантифікатори вказують, скільки разів елемент повинен з’явитися в рядку, і визначаються фігурними дужками {}.
Наприклад, шаблон T{5} означає, що літера T повинна послідовно з’являтися п’ять разів.
** T {3,6} ** - від трьох до шести разів
T{5,} - п’ять разів чи більше.
Якоря та межі слів
Якщо потрібно вказати, що шаблон повинен бути на початку або в кінці рядка, використовують якорі.
Символ каретки (^) призначений для прив’язки шаблону до початку рядка. Наприклад, ^[1-5] означає, що відповідний рядок має починатися з однієї із цифр від 1 до 5. Символ $ використовується для прив’язки шаблону до кінця послідовності чи рядка.
Наприклад, [1-5]$ означає, що рядок повинен закінчуватися однією із цифр від 1 до 5.
** Капелюшок (^) може ще позначати логічне заперечення!
$ - кінець рядка
приклад.
^Name:[\sa-zA-Z]+$
Приклади регулярних виразів.
Перевірка телефону.
/\d+[-s]?\d+[-s]?\d+/
[-\s] - дефіс або пробіл
Варіанти перевірки email
/^[\w-\.]+@([\w-]+\.)+[\w-]{2,4}$/
ˆ[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)* @ [a-zA-Z0-9-]+\.([azA-Z]{2,3})$
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Ось така “жесть” для розуміння цього регулювання!
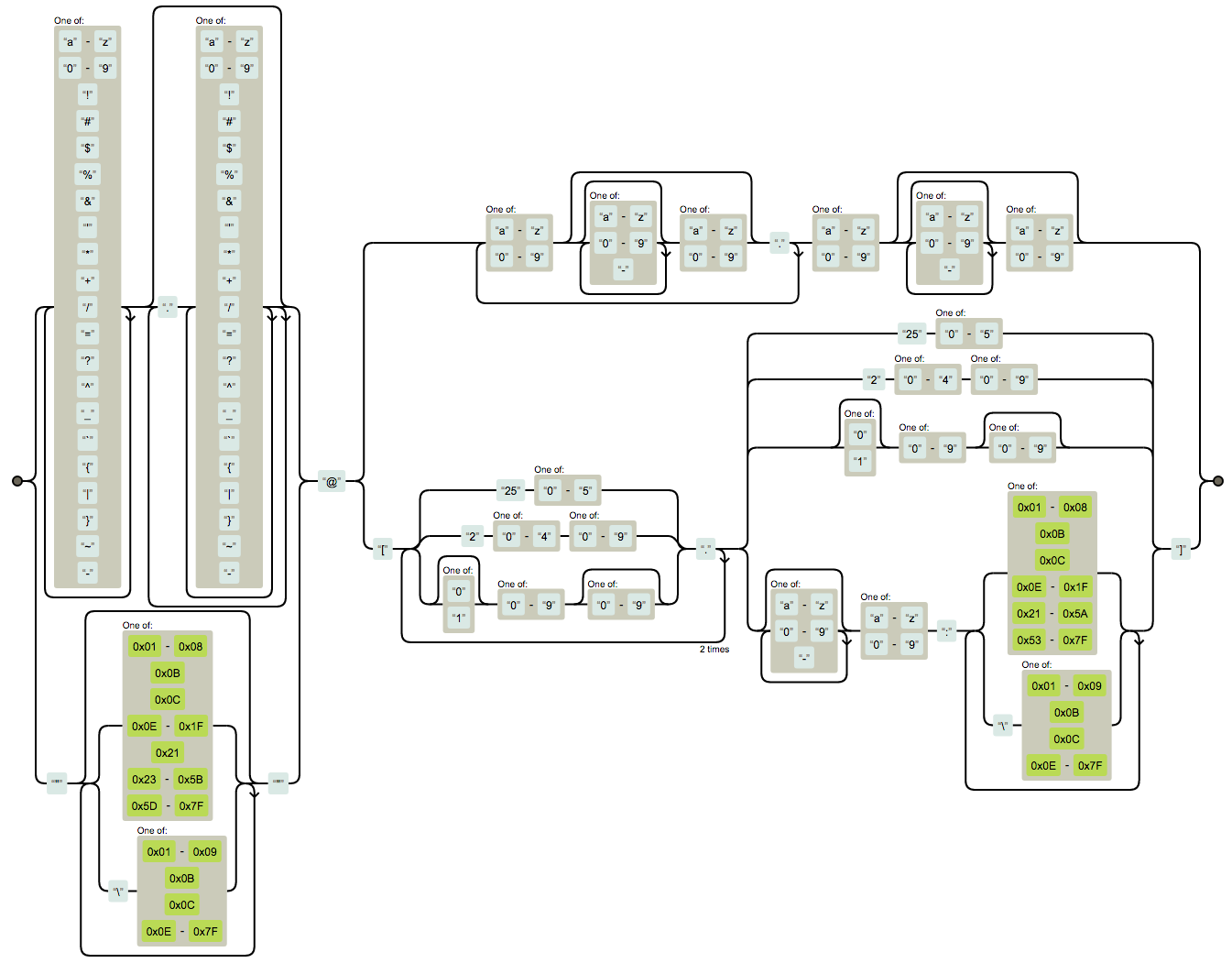
Перевірка ip адреси
((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)(\.|$)){4}
Регулярний вираз у Python.
Імпорт пакету.
import re
Далі ми повинні відкомпілювати регулювання в байт-код, здатний до виконання C.
pattern = re.compile('foo')
Під час компіляції можна вказувати прапори.
pattern = re.compile("^\w+\: (\w+/\w+/\w+)", re.MULTILINE)
re.MULTILINE - компілюватиме для пошуку у всіх рядках, якщо його не вказати, то шукатиме тільки в першому.
Після компіляції нам повертається об’єкт, який підтримує пошук та інші операції.
Пошук збігів.
pattern.match("foo bar")
pattern.search("Hello world")
Ця система поверне об’єкт MatchObject збігу або None.
Дістаємо збіги з MatchObject групами.
match.group()
match.group(0)
match.group(1)
Повертаємо перелік збігів.
list = pattern.findall("hello world")
Регулярний вираз у JavaScript.
Тут все набагато простіше.
var email = "joerg@krause.net";
console.log(check(email));
function check(email) {
if (email.match(/^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*@[a-zA-Z0-9-]+\\
.([a-zA-Z]{2,3})$/)) {
return true;
} else {
return false;
}
}
Як видно рядки в js-ці вміють приймати регулярку в методі match
Для тих, хто цікавиться, наведу докладний виклад послідовності цієї перевірки.

Ручне створення шаблону та тестування.
var patt = /^auto$/;
console.log(patt.test("auto"));
Другий варіант з exec().
<script>
var re = /^[0-9]{5}$/;
var field = "12683";
var checkzip = re.exec(feld);
if(!checkzip) {
alert("The zip code " + checkplz + " is not correct.");
} else {
console.log(checkplz)
}
</script>
Об’єкт для роботи з регулюванням RegExp
Методи об’єкту
exec() - тестує та повертає перше влучення
test() - тестує та повертає true або false
toString() - повертає вираз як рядок
приклад.
var text = "Than Ann answers all questions again.";
var patt = /a/g;
var match = patt.exec(text);
console.log(match[0] + " found at " + match.index);
match = patt.exec(text);
do {
match = patt.exec(text);
if (!match) break;
console.log(match[0] +" found at " + match.index);
} while(true);
Висновок.
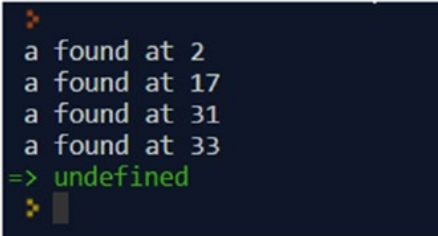
Як бачимо, для того щоб пробігатися по всіх збігах, необхідно “крутити” цикл, де викликати exec() і переривати його коли збіги закінчаться.
if (! match) break;