Основи Python и Django. / Практикум. Перевіряємо домени з терміном, що закінчується. / Перевіряємо домени, що закінчуються.
Проверяем домены с истекающим сроком.
Недавно от “насяльника” мне поступила такая задача:
“Димыч скажи пож вот отсюда - https://www.reg.ru/domain/deleted/?&free_from=07.06.2019&free_to=07.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page=5 можно сграбить названия доменов?”
Я зайшов за посиланням, побачив список доменів, у яких закінчується термін, посторінкову навігацію та всі справи.
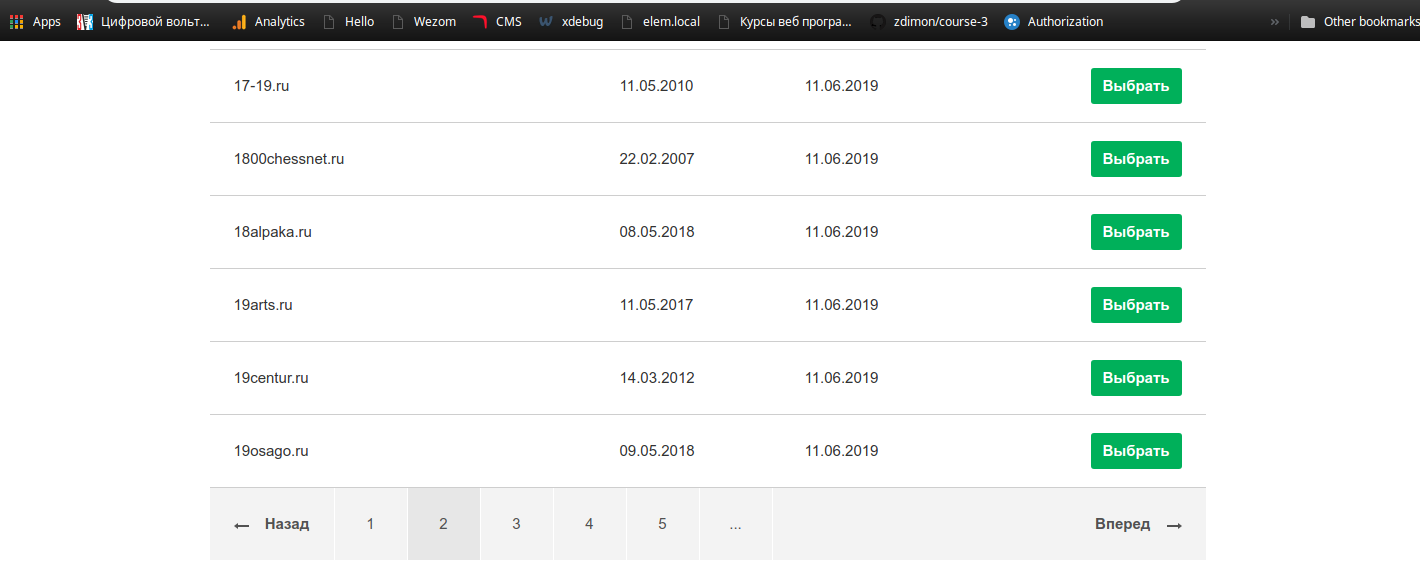
Я подумав “Чому б і ні?” буду пробігати по сторінці, змінюючи параметр page=1,2,3 в урлі, парсить сторінки і зберігати домени.
Що може бути простішим?
Потім надійшло доповнення до завдання. Як виявилося, ці домени потрібно перевіряти на присутність на одному сайті, скажімо yandex.ru:
Наприклад, ось так:
https://yandex.ru/sabai.tv
Куди замість sabai.tv підставляти мої пограбовані доменчики.
З цим начебто проблем бути не повинно. Тим більше, що за відсутності домену в цьому інтернет-каталозі, він повертає 404 помилки.
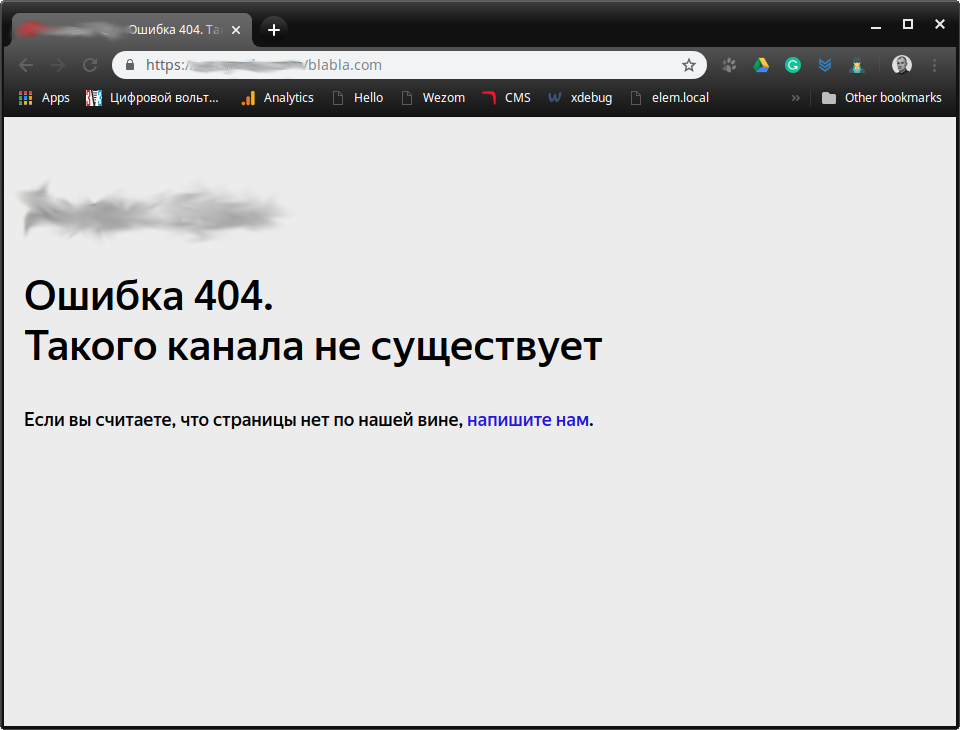
Прийдеться трохи заддосить напружити цей сайт.
Тож поїхали.
Мені знадобляться дві пітонівські бібліотеки:
requests - для створення HTTP GET запитів
beautifulsoup4 - для парсингу HTML та пошуку корисної інформації на сторінці.
Все це добро складемо у віртуальне оточення.
Створюю та активую його.
mkdir finedomain
cd finedomain
virtualenv venv
source ./venv/bin/activate
Ставлю пакунки.
pip install requests beautifulsoup4
Пишу код із запитом у файлі grabing.py.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Імпортуємо все що треба для роботи import requests from bs4 import BeautifulSoup import json import time import sys # початок програми print(‘Start’) # визначаю рядок з урлом # до неї з кінця приліплюватиму сторінки url = ‘https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page=’
# запит першої сторінки
r = requests.get(url+'0')
print(r.text)
Результат.
Непогано, HTML отримали, далі потрібно розпарити це все добро beautifulsoup-ом.
soup = BeautifulSoup(r.text, 'html.parser')
Тепер у змінній soup у нас не тільки весь код сторінки, але й інструменти для пошуку її елементів.
Відкидаємо інспектор браузера і дивимося, де у нас список.
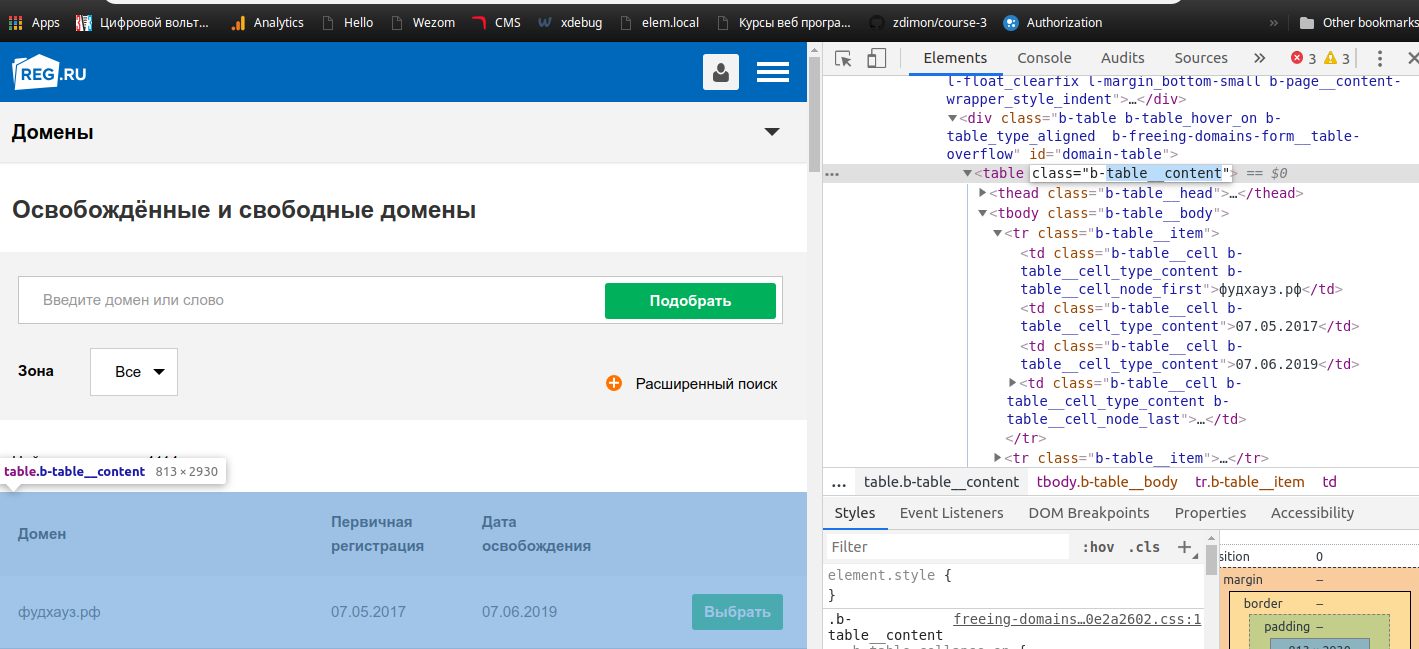
га, таблиця з класом b-table__content. Немає нічого простішого її витягнути так.
table = soup.find("table",{"class": "b-table__content"})
find() - шукає один елемент findAll() - знайде список
Далі отримаю tr-ки (рядки) з тега tbody.
tbody = table.find("tbody")
trs = tbody.findAll("tr")
Втечу за ними циклом, знайду td-шки (комірки таблиці) і виведу з першої за рахунком доменне ім’я.
soup = BeautifulSoup(r.text, 'html.parser')
table = soup.find("table",{"class": "b-table__content"})
tbody = table.find("tbody")
trs = tbody.findAll("tr")
for tr in trs:
tds = tr.findAll("td")
print(tds[0].text)
Спрацювало!
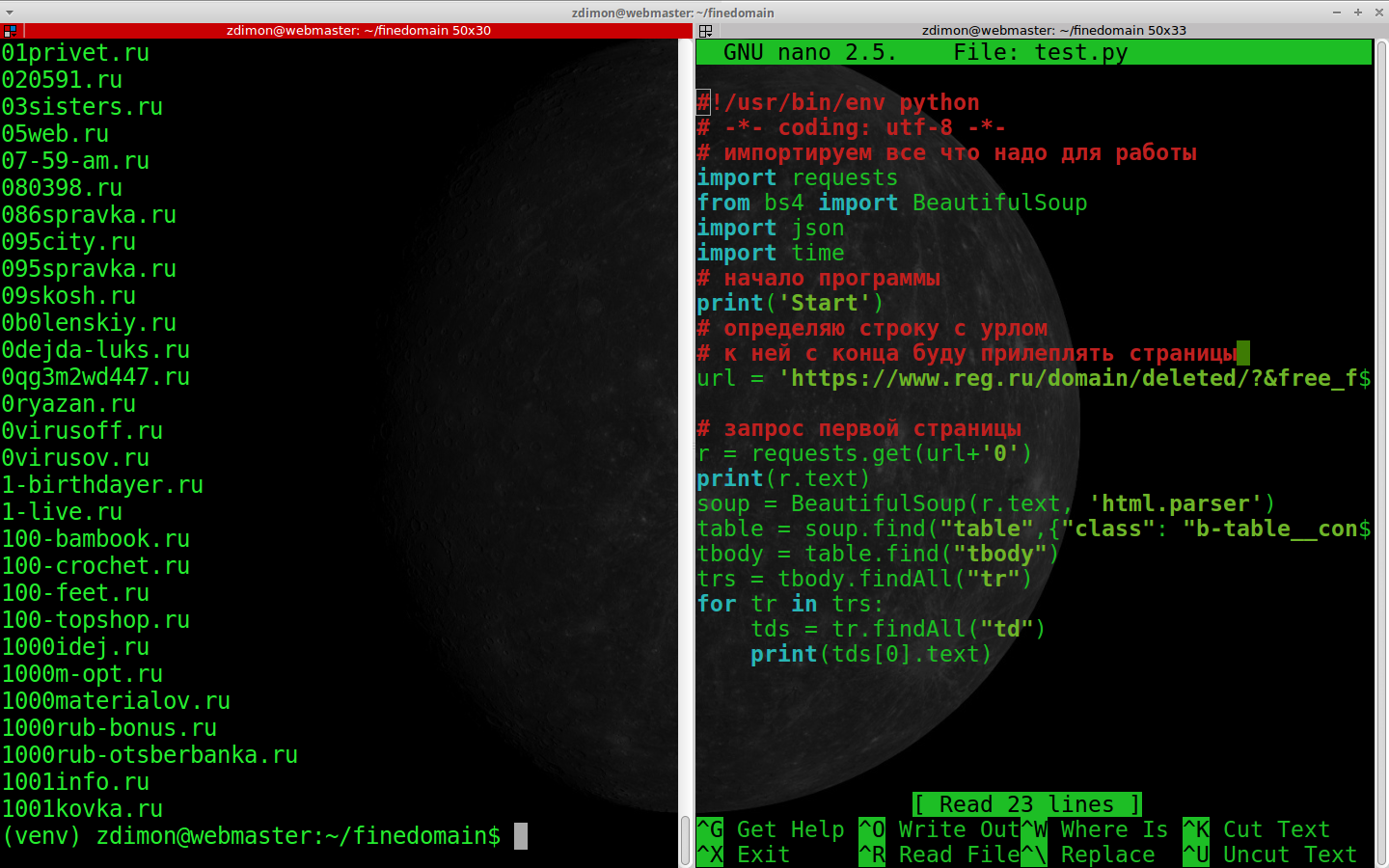
Тепер створимо список для зберігання доменів та дати закінчення, і в циклі заповнюю його.
Повний код вийшов таким.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Імпортуємо все що треба для роботи
import requests
from bs4 import BeautifulSoup
import json
import time
# початок програми
print('Start')
# визначаю рядок з урлом
# до неї з кінця приліплюватиму сторінки
url = 'https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page='
# запит першої сторінки
r = requests.get(url+'0')
# тут зберігатиму домени
data = []
# Парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# знаходимо першу таблицю за тегом та css класом
table = soup.find("table",{"class": "b-table__content"})
# в ній блок tbody на ім'я тега
tbody = table.find("tbody")
# рядки
trs = tbody.findAll("tr")
for tr in trs:
# осередки
tds = tr.findAll("td")
# додаємо домен та термін закінчення до списку
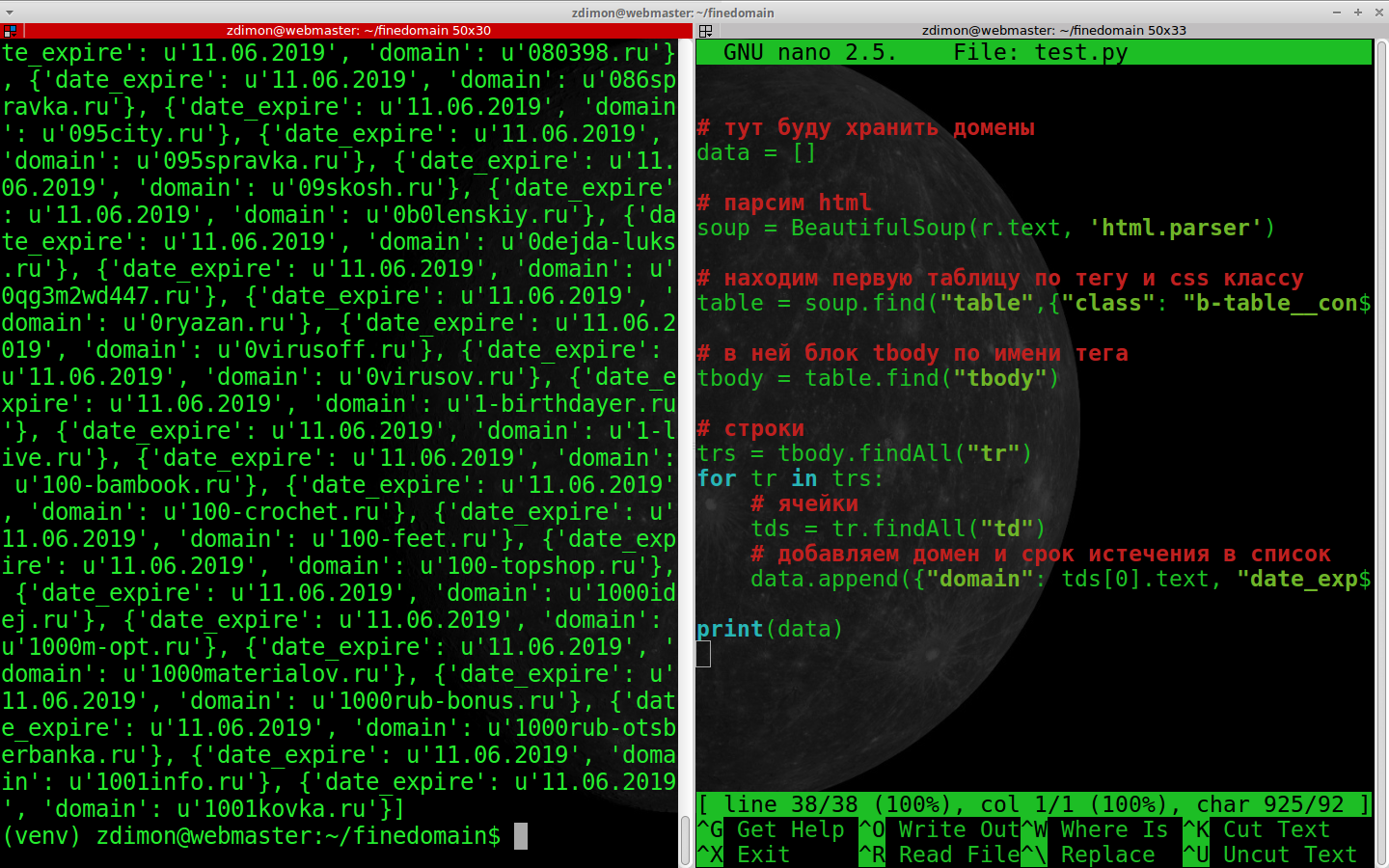
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
print(data)
Час перевірити ці домени на сайті.
Зроблю при цьому функцію, яка приймає доменне ім’я параметром.
def check_domain(domain):
# формую url, адресу підставляючи домен у рядок
url = 'https://yandex.ru/%s' %domain
# пробую зробити запит
try:
# отримую сторінку
r = requests.get(url)
if r.status_code == 404: # проверяю статус
print('Domain %s result %s' % (domain, 'FAIL!'))
return False
else:
print('Domain %s result %s' % (domain, 'SUCCESS'))
# якщо пощастило і домен знайшли
return True
# це якщо запит обрушився з якоїсь причини
except:
print('Request error %s' % url)
return False
Залишилось викликати цю функцію у циклі.
for tr in trs:
# осередки
tds = tr.findAll("td")
# додаємо домен та термін закінчення до списку
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# перевіряю домен
check_domain(tds[0].text)
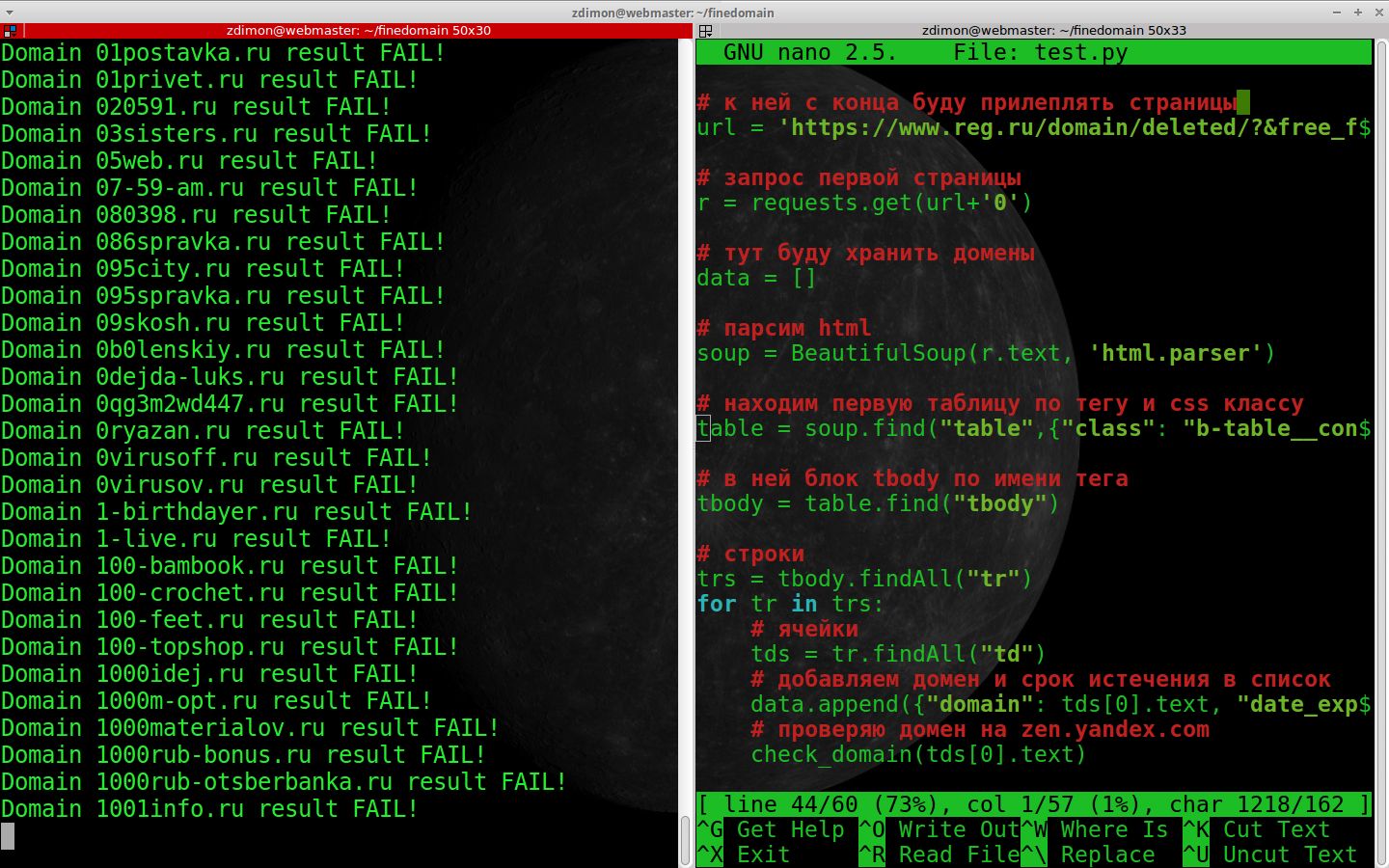
Результат не втішає і попадань на першій сторінці немає, проте працює!
Тепер мені потрібно визначити кінець посторінкової “нафігації” та прогнати процес по всіх доменах на зазначену дату.
У найкращих традиціях функціонального програмування виконую функцію.
def check_end(soup):
'''Визначаю кінець сторінки '''
try:
# на кінцевій сторінці було помічено заголовок h1 з текстом
'''
Доменів, що відповідають заданим критеріям фільтрації, не знайдено.
'''
h2 = soup.find("h2")
# тут для пошуку сказало, що потрібно спочатку кодувати в UTF-8
if h2.text.encode('utf-8').find('що відповідають заданим критеріям')>0:
return True
else:
return False
except:
return False
Мучу цикл while поки не дійшло до кінця з лічильником сторінок.
is_end = False
page = 0
while not is_end:
# визначаю рядок з урлом
# до неї з кінця приліплюватиму сторінки
url = 'https://www.reg.ru/domain/deleted/?&free_from=12.06.2019&free_to=12.06.2019&order=ASC&sort_field=dname_idn%20%20%20%20&page=%s' % page
print("Роблю сторінку %s" % page)
# додаємо лічильник сторінок
r = requests.get(url)
# тут зберігатиму домени
data = []
# Парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# перевіримо кінець постранички
if check_end(soup):
is_end = True
break # ламаємо цикл
# знаходимо першу таблицю за тегом та css класом
table = soup.find("table",{"class": "b-table__content"})
# в ній блок tbody на ім'я тега
tbody = table.find("tbody")
# рядки
trs = tbody.findAll("tr")
for tr in trs:
# осередки
tds = tr.findAll("td")
# додаємо домен та термін закінчення до списку
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# перевіряю домен
check_domain(tds[0].text)
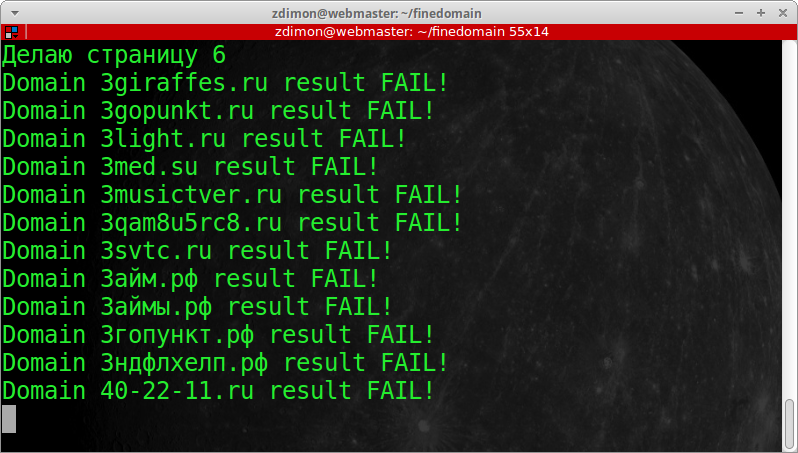
Решил прервать процесс по ctrl+c, получил такой облом.
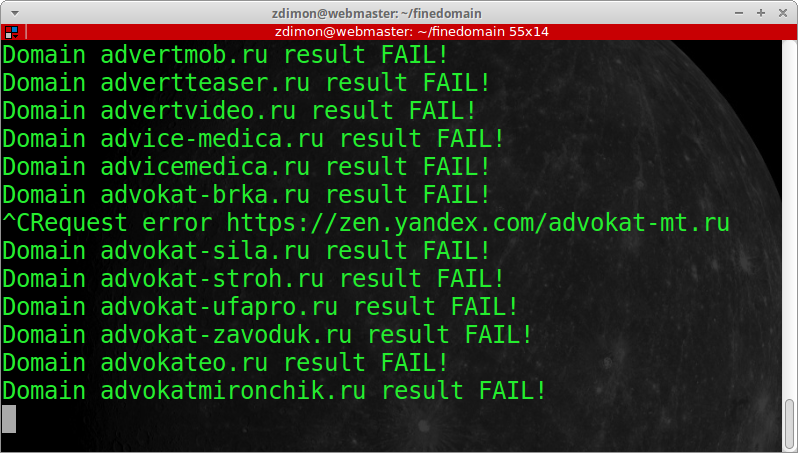
Довелося гасити термінал, образливе непорозуміння.
Сталося воно у цьому блоці під час перевірки домену:
except:
print('Request error %s' % url)
return False
А якщо я відпрацюю виняток KeyboardInterrupt?
try:
# отримую сторінку
...
except KeyboardInterrupt: # вихід ctrl+c
print("Ну поки що!")
sys.exit() # нахабно вивалюється з проги
# це якщо запит обрушився з якоїсь іншої причини
except:
print('Request error %s' % url)
return False
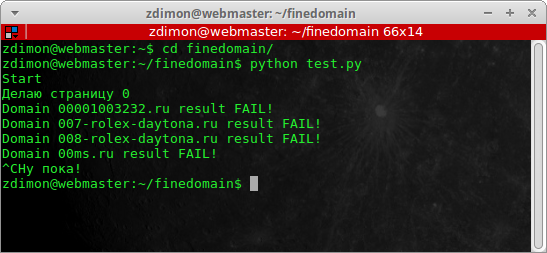
Набагато краще!
Залишилося забрати дату у користувача десь на початку скрипту.
print("Введи дату типу 12.06.2019: ")
user_date = raw_input() #
print("Працюємо по {}".format(user_date))
Просто input() не канає! Використовуйте тільки raw_input.
І вставити її до урла запиту.
Наприкінці я вивантажу успішні домени у файл.
def save_success(domain):
with open('success.txt', 'a+') as of: # открываем для добавления и создаем если нет
of.write(domain+';')
print('Domain %s result %s' % (domain, 'SUCCESS'))
Повний код програми.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Імпортуємо все що треба для роботи
import requests
from bs4 import BeautifulSoup
import json
import time
import sys
# початок програми
print('Починаємо грабувати домени.')
print("Вводь за яку дату? (типу 12.06.2019): ")
user_date = raw_input()
print("Працюємо по {}".format(user_date))
def save_success(domain):
with open('success.txt', 'a+') as of: # відкриваємо для додавання та створюємо якщо ні
of.write(domain+';')
print('Domain %s result %s' % (domain, 'SUCCESS'))
def check_domain(domain):
# формую url, адресу підставляючи домен у рядок
url = 'https://yandex.ru/%s' % domain
# пробую зробити запит
try:
# отримую сторінку
r = requests.get(url)
if r.status_code == 404: # перевіряю статус
print('Domain %s result %s' % (domain, 'FAIL!'))
return False
else:
print('Domain %s result %s' % (domain, 'SUCCESS'))
# якщо пощастило і домен знайшли
return True
except KeyboardInterrupt: # вихід по ctrl+c
print("Ну поки що!")
sys.exit() # нахабно вивалюється з проги
# це якщо запит обрушився з якоїсь причини
except:
print('Request error %s' % url)
return False
def check_end(soup):
''Визначаю кінець сторінки '''
try:
# на кінцевій сторінці було помічено заголовок h1 з текстом
'''
Доменів, що відповідають заданим критеріям фільтрації, не знайдено.
'''
h2 = soup.find("h2")
# тут для пошуку сказало, що потрібно спочатку кодувати в UTF-8
if h2.text.encode('utf-8').find('що відповідають заданим критеріям')>0:
return True
else:
return False
except:
return False
is_end = False
page = 0
while not is_end:
# визначаю рядок з урлом
# до неї з кінця приліплюватиму сторінки
url = 'https://www.reg.ru/domain/deleted/?&free_from=%s&free_to=%s&order=ASC&sort_field=dname_idn%20%20%20%20&page=%s' % (user_date,user_date,page)
print("Роблю сторінку %s" % page)
# додаємо лічильник сторінок
r = requests.get(url)
# тут зберігатиму домени
data = []
# Парсим html
soup = BeautifulSoup(r.text, 'html.parser')
# перевіримо кінець постранички
if check_end(soup):
is_end = True
break # ламаємо цикл
# знаходимо першу таблицю за тегом та css класом
table = soup.find("table",{"class": "b-table__content"})
# в ній блок tbody на ім'я тега
tbody = table.find("tbody")
# рядки
trs = tbody.findAll("tr")
for tr in trs:
# осередки
tds = tr.findAll("td")
# додаємо домен та термін закінчення до списку
data.append({"domain": tds[0].text, "date_expire": tds[2].text})
# перевіряю домен
if check_domain(tds[0].text):
save_success(tds[0].text)
print('The end')
Висновки.
У статті висвітлено прийоми програмування мовою Python на прикладі реального, практичного завдання.
Викладено основні функції Python бібліотек requests та BeautifulSoup для отримання вмісту сторінки , пошуку та вилучення з неї корисної інформації зі збереженням у текстовий файл.